在當(dāng)今數(shù)據(jù)爆炸的時代,如何高效處理海量、多樣、高速的數(shù)據(jù)成為企業(yè)和技術(shù)人員面臨的核心挑戰(zhàn)。Hadoop作為大數(shù)據(jù)處理領(lǐng)域最著名、最成熟的開源框架,自誕生以來,便以其分布式、可擴(kuò)展、高容錯的特性,構(gòu)建了現(xiàn)代大數(shù)據(jù)處理的基石。其數(shù)據(jù)處理能力,特別是通過其核心組件MapReduce和YARN,定義了一個經(jīng)典且強(qiáng)大的數(shù)據(jù)處理范式。
一、Hadoop生態(tài)系統(tǒng)概述
Hadoop并非單一軟件,而是一個由多個相關(guān)項(xiàng)目構(gòu)成的生態(tài)系統(tǒng)。其核心是Hadoop Common(公共模塊)、Hadoop Distributed File System (HDFS) 和 Hadoop YARN。
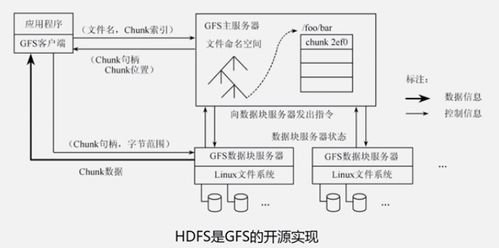
- HDFS:是Hadoop的存儲基礎(chǔ)。它將大文件切分成固定大小的數(shù)據(jù)塊(Block),并分布式地存儲在集群的多個節(jié)點(diǎn)上,同時通過多副本機(jī)制實(shí)現(xiàn)高容錯性和高可用性。其“一次寫入,多次讀取”的模型非常適合大數(shù)據(jù)批處理場景。
- YARN:是Hadoop 2.0引入的資源管理和作業(yè)調(diào)度平臺。它將資源管理與具體的計(jì)算框架解耦,使得Hadoop集群能夠同時運(yùn)行MapReduce、Spark、Flink等多種計(jì)算框架,極大地提升了集群的資源利用率和靈活性。
二、核心數(shù)據(jù)處理范式:MapReduce
MapReduce是Hadoop最初的數(shù)據(jù)處理引擎,其編程模型簡單而強(qiáng)大,將復(fù)雜的數(shù)據(jù)處理任務(wù)分解為兩個主要階段:
- Map階段:由多個Map任務(wù)并行執(zhí)行。每個任務(wù)讀取輸入數(shù)據(jù)的一個分片(Split,通常對應(yīng)HDFS的一個數(shù)據(jù)塊),執(zhí)行用戶定義的
map()函數(shù),將輸入鍵值對轉(zhuǎn)換為一系列中間鍵值對。這個過程是“分而治之”的體現(xiàn)。 - Shuffle與Sort階段:這是框架自動完成的“幕后英雄”。系統(tǒng)會將所有Map任務(wù)產(chǎn)生的中間結(jié)果,根據(jù)鍵(Key)進(jìn)行分區(qū)、排序和合并,然后分發(fā)給相應(yīng)的Reduce任務(wù)。這個階段是網(wǎng)絡(luò)數(shù)據(jù)傳輸最密集的部分,也是性能優(yōu)化的關(guān)鍵點(diǎn)之一。
- Reduce階段:由多個Reduce任務(wù)并行執(zhí)行。每個Reduce任務(wù)接收屬于自己分區(qū)的、已經(jīng)排序的中間鍵值對,執(zhí)行用戶定義的
reduce()函數(shù),對具有相同鍵的值進(jìn)行聚合、計(jì)算,最終產(chǎn)生輸出結(jié)果,并寫入HDFS。
經(jīng)典應(yīng)用:詞頻統(tǒng)計(jì)(WordCount)是理解MapReduce的最佳入門案例。Map任務(wù)將文檔拆分成單詞并輸出 <單詞, 1>,Shuffle階段將相同單詞聚集到一起,Reduce任務(wù)則對每個單詞的“1”列表進(jìn)行求和,得到每個單詞的總出現(xiàn)次數(shù)。
三、數(shù)據(jù)處理的優(yōu)勢與挑戰(zhàn)
優(yōu)勢:
1. 高可擴(kuò)展性:通過簡單增加廉價的商用服務(wù)器(節(jié)點(diǎn))即可線性擴(kuò)展存儲和計(jì)算能力。
2. 高容錯性:數(shù)據(jù)在HDFS上有多個副本,計(jì)算任務(wù)失敗后可由YARN在其它節(jié)點(diǎn)上重新調(diào)度執(zhí)行。
3. 成本效益:基于開源軟件和通用硬件,構(gòu)建大規(guī)模集群的成本遠(yuǎn)低于傳統(tǒng)大型機(jī)和高端存儲。
4. 適合批處理:對TB/PB級別的歷史數(shù)據(jù)進(jìn)行離線分析、數(shù)據(jù)挖掘、日志處理等場景優(yōu)勢明顯。
挑戰(zhàn)與演進(jìn):
1. 延遲高:MapReduce的中間結(jié)果需要寫磁盤,且任務(wù)調(diào)度開銷大,導(dǎo)致處理延遲通常在分鐘甚至小時級,不適合實(shí)時或交互式查詢。
2. 編程模型相對固定:復(fù)雜的多階段計(jì)算需要串聯(lián)多個MapReduce作業(yè),開發(fā)效率較低。
3. 生態(tài)系統(tǒng)演進(jìn):正因?yàn)檫@些挑戰(zhàn),以Spark為代表的新一代內(nèi)存計(jì)算框架迅速崛起。Spark基于RDD/DataFrame模型,通過內(nèi)存計(jì)算和更豐富的算子( transformations和actions),在保持容錯性的將處理速度提升了數(shù)十倍到百倍,并更好地支持流處理、機(jī)器學(xué)習(xí)和圖計(jì)算。如今,Spark常運(yùn)行在由YARN管理的Hadoop集群上,復(fù)用HDFS進(jìn)行存儲,形成了優(yōu)勢互補(bǔ)的架構(gòu)。
四、現(xiàn)代Hadoop數(shù)據(jù)處理架構(gòu)
一個典型的現(xiàn)代大數(shù)據(jù)處理平臺往往采用分層架構(gòu):
- 存儲層:以HDFS為核心,可能結(jié)合對象存儲(如S3)或NoSQL數(shù)據(jù)庫(如HBase)。
- 資源管理層:由YARN統(tǒng)一調(diào)度集群的CPU、內(nèi)存等資源。
- 計(jì)算引擎層:根據(jù)場景選擇不同引擎。批處理可選用MapReduce或Spark;交互式查詢可選用Hive(將SQL轉(zhuǎn)化為MapReduce/Spark任務(wù))或Impala/Presto;流處理可選用Spark Streaming或Flink;機(jī)器學(xué)習(xí)可選用Spark MLlib。
- 數(shù)據(jù)管理與服務(wù)層:包括元數(shù)據(jù)管理(Hive Metastore)、工作流調(diào)度(Azkaban, Oozie)、數(shù)據(jù)集成(Sqoop, Flume)等。
結(jié)論
Hadoop開啟了大數(shù)據(jù)的工業(yè)化處理時代。盡管其原生的MapReduce引擎在實(shí)時性上已非首選,但HDFS和YARN構(gòu)成的穩(wěn)定、可靠的存儲與資源管理底座,依然是眾多企業(yè)大數(shù)據(jù)平臺的基石。理解Hadoop的數(shù)據(jù)處理架構(gòu)——從HDFS的分布式存儲,到MapReduce的批處理模型,再到Y(jié)ARN的資源統(tǒng)一管理——是深入大數(shù)據(jù)技術(shù)領(lǐng)域的必經(jīng)之路。今天,我們更應(yīng)將其視為一個強(qiáng)大的生態(tài)基石,在其之上靈活選用Spark、Flink等更高效的計(jì)算引擎,共同構(gòu)建滿足多樣化需求的數(shù)據(jù)處理解決方案。